AI Infrastructure Tools

We are on the brink of a new industrial age; Just as with the first industrial age, the tool smiths will lead the revolution.
L.L.M. Chatbot Organisation
By now, most folks have interacted with an A.I. (LLM) chatbot. These answer questions by making use of large language models (LLMs). Strangely, instead of instantly filling the page with 100s of results, as search engines do, they progressively, and often quite slowly, type out each word of the answer in succession. This is more than a gimmick; it is inherent in how LLMs work.
Large Language Models (LLMs)
An LLM is a data model generated from big data repositories. Without the Internet, we were unlikely to generate big data; without big data, we would never have had LLMs.
LLMs are generally a single file of around 4 GB to 400 GB. Each can be used to build an LLM chatbot that can answer questions on various topics. All the knowledge is held in that single file in a highly compressed form. Where that data came from and how the compression was achieved distinguishes one LLM from another.
Smaller LLM files enable chatbots to run on smaller RAM computers; Less compressed LLM files enable more efficient, and therefore generally faster, chatbots.
Generating, aka training, an LLM (file) takes some time and a lot of computing power to build. Providers often have release schedules of around 6 months. The state of the art of LLM production is constantly evolving, often in leaps and bounds. The big data source is generally as broad as the Internet (where they are usually taken from), and domain-specific LLMs continue to evolve, such as programming language, art, etc.
There are many open-source LLMs available.
LLM Chatbot Infrastructure Components
To function, an LLM chatbot needs these infrastructure components
-
A chat client interface — the “frontend” in the diagram above — takes the users’ questions and spits back a word-by-word response. It might present as (i) a web app or (ii) a monolithic mobile or desktop application, or (iii) a dedicated chat-client application.
-
An LLM engine – “backend API server” in the diagram above – This interacts with the LLM file to generate the answer that the chat interface presents to the user; These engines have an (usually HTTP-based) API interface to the chat-client. They require access to the LLM file to operate and can usually select from multiple available LLM files (though generally, only one at a time). To operate efficiently, (i) they are best when able to load the entire LLM into available RAM, and (ii) benefit from a lot of available CPU and/or GPU cycles to compute the answer to the question.
Companies such as OpenAI often provide a backend API service. These companies have the computer resources to serve clients concurrently and benefit from economies of scale. This engine function also can be incorporated into monolithic applications and web apps.
A backend API server, is not a web server or a web-site, but it may come packaged with a web interface.
-
The LLM file, itself – LLM Model in the diagram above – selection is often down to the domain being questioned, the available computing resources, and brand loyalty.
-
LLM Augmentation – the orange box in the diagram above – this is an important area of active research. The solution can be augmented with specific knowledge unavailable within the LLM file, such as interrogation of supplied private documents or initiated internet searches, or local database searches. This is referred to as Retrieval-Augmented Generation (RAG).
Currently, these augmented data sources are generally used before the LLM file is processed. This facility extends the use of the LLM chatbot beyond that of the data used in training the LLM.
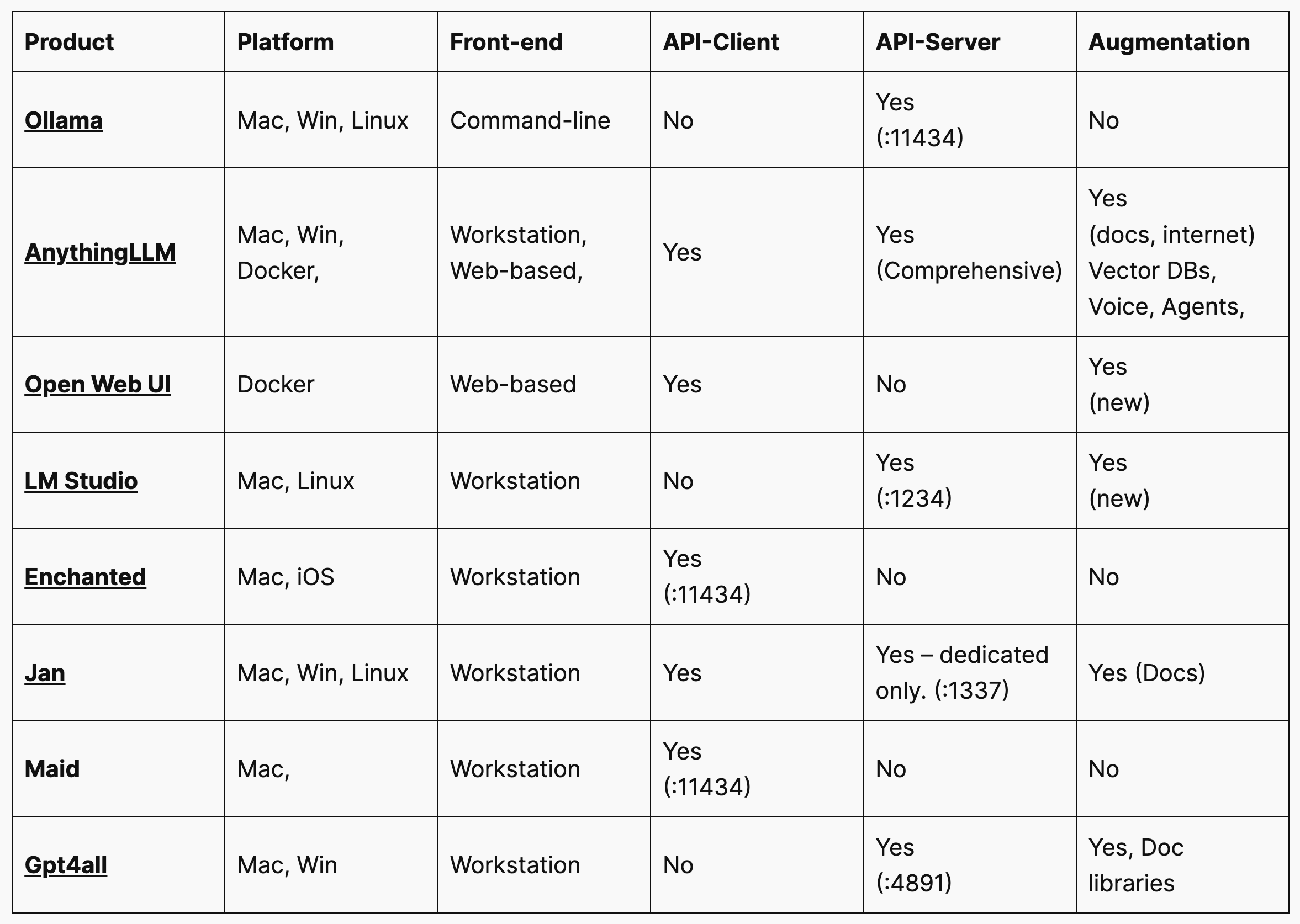
Small Survey of Infrastructure Tools
Here is a survey of some of these infrastructure tools Itchy Studio has experienced as of September 2024.
Review
 |
Ollama works well as a small dedicated API server for llama models; if you prefer to chat from the command line, that also works nicely. It can be front-ended by AnythingLLM docker server or Open Web UI, to provide a web-interface accessible from the internet. |
 |
Anything LLM comes in both (i) the (Windows and Mac) workstation system and (ii) the docker server system. The workstation system gets newbies up and running quickly with a tool that they can extend to do RAG and run locally on their laptops. The docker server system can be easily web-hosted. Both systems can be extended to different vector DBs and can work as a client to many back-end engines. RAG is well accounted for with the AnythingLLM tooling doing the RAG. Customisation and extendability are its strengths and it can be configured to serve multiple independent groups of users, each with their own configurations. |
 |
Open Web UI, previously called Ollama Web UI, provides a web interface to backend API servers. It is a simple dockerised server setup that has started to provide document RAG facilities. The backend API server does the main work, so it has a low memory and CPU footprint. It supports various LLM runners, including Ollama and OpenAI-compatible APIs, so you can use it with self-hosted LLMs or external services. Its strength is as a locally hosted web interface; it has only very limited features to provide service to others. |
| LM Studio is a self-contained (Apple-silicon Mac) workstation product, that can also function as an API server. Its strength is as a stand-alone ‘studio’ product, i.e. the place where one might install a number of LLM files and compare their facilities and responses. Indeed one trick it has is to be able to concurrently load multiple LLMs and send a question to all as many concurrently loaded models as you wish, identifying each answer with a different colour. It does not have an API client facility, so to use it on other machines, use something like Open Web UI or AnythingLLM. There are many other products which are somewhat equivalent to LM Studio, such as **gpt4all** which has good local document RAG. |
 |
GPT 4All is a self-contained workstation product, that can also function as an API server. It has a document library RAG as well. |
 |
Enchanted and Maid These both are Mac (and iOS) API Client apps. They are to be used with API servers such as Ollama (not so much LM Studio). Their advantage is being able to run the client on a different machine to the server, so one could offload a model engine to a computer not ordinarily used as a workstation. This is a common requirement. We have not been able to get either of these to run 100% reliably yet with LM Studio, but had OK results with the Ollama server. We would like RAG functions as well. Features include voice support, read-aloud, completions and markdown. |
API Service Providers
Being your own API service provider is great when you have available computing resources and are happy to stand up the service yourself. But if you don’t or aren’t, 3rd-party service providers are the way to go.
Open AI’s chat-GPT API service is a well-established choice, but there are others.
 |
Akash Network is a decentralised physical infrastructure network (DePIN) provider. They thrive on LLMs thirst for compute resources. As a promotion, Akash makes available a Llama 3.1 API (both 8B and 405B) that is compatible with Open AIs. It is a good way to get started. |